�ȸ��������惞��SEO�������ύrobots.txt�ļ�
���ڣ�2025��1��15��������ʹ�� robots.txt �ļ�����ץȡ���߿����L�����Wվ�ϵ���Щ�ļ���robots.txt �ļ���λ�ھWվ�ĸ�Ŀ��¡���ˣ����ھWվ www.exam�ȸ�����������ô����

������ʹ�� robots.txt �ļ�����ץȡ���߿����L�����Wվ�ϵ���Щ�ļ���robots.txt �ļ���λ�ھWվ�ĸ�Ŀ��¡���ˣ����ھWվ www.exam�ȸ�����������ô����
����������Ҫ����Ҫӆ�Σ�һ���þWվ���HҪ�M���Ñ�����߀Ҫ����SEOҎ�t��
SEO�Č��I���h����������҂�Ҫ�����Džf������������������_�������漰���IJ�ֹ�ǾWվ�Y���������|�����Ñ��w�ⲿ朽��@�ׂ����棻߀���㷨�ĸ��桢֩������������յĸ��¡����c����ę��صȡ�
һ���Ñ��ѵ���ľWվ����SEO������Ŀ��,���о�տ��SEO���g���S���Ľ����Լ���SEOҎ�t����̰��ղ��ЙC���@�ø���չ�F�C����
�����_���Wվ�����������ʴ_����������,ʹ�Ñ��܉��p���ҵ�������Ϣ.ʹ�ú������˵Ę��}������,�����Ñ������˽���ĮaƷ���գ�
��������I�ĺ��ărֵ������u�c����������������Z��Ʒ���~�M���ܶ��ռλ����ǰ���,�����Ñ�ӡ�����Ñ��w��L�������㣡
�ġ��������������Ñ���ԃ���A�s����,���ô��Ͱ��������������@Ʒ�ƌ���,�Pע�Ñ�����ͷ���,���������aƷ�����Ñ��x���㣡
�Ñ��ѵ��㡢�����㡢�x���㣡
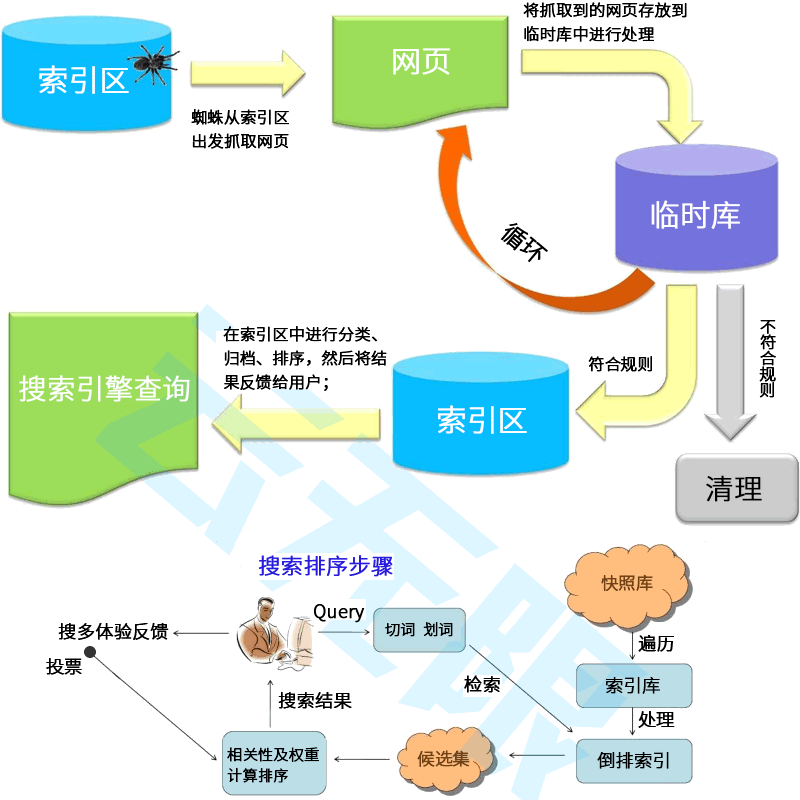
������ʹ�� robots.txt �ļ�����ץȡ���߿����L�����Wվ�ϵ���Щ�ļ���robots.txt �ļ���λ�ھWվ�ĸ�Ŀ��¡���ˣ����ھWվ www.example.com��robots.txt �ļ���·������ www.example.com/robots.txt��robots.txt ��һ�N��ѭ�������ų��˜ʵļ��ı��ļ�����һ�l����lҎ�t�M�ɡ�ÿ�lҎ�t�ɽ�ֹ�����S�ض�ץȡ����ץȡ�����Wվ��ָ���ļ�·���µ��ļ����������� robots.txt �ļ�������ָ������t�����ļ����[ʽ���Sץȡ��
������һ�������ɗlҎ�t�ĺ��� robots.txt �ļ���
User-agent: Googlebot
Disallow: /nogooglebot/
User-agent: *
Allow: /
Sitemap: http://www.example.com/sitemap.xml
������ԓ robots.txt �ļ��ĺ��x��
1������ Googlebot ���Ñ���������ץȡ�κ��� http://example.com/nogooglebot/ �_�^�ľWַ��
2�����������Ñ���������ץȡ�����Wվ����ָ���@�lҎ�tҲ�o�����Y����һ�ӵģ�Ĭ�J�О����Ñ���������ץȡ�����Wվ��
3��ԓ�Wվ��վ�c�؈D�ļ�·���� http://www.example.com/sitemap.xml��
����鿴����ʾ����Ո����Z�����֡�
Ҫ���� robots.txt �ļ���ʹ����һ����r�¾߂���L���Ժ͌����ԣ���Ҫ��� 4 �����E��
1������һ������ robots.txt ���ļ���
2���� robots.txt �ļ�����Ҏ�t��
3���� robots.txt �ļ��ς������ľWվ��
4���yԇ robots.txt �ļ���
��������ʹ�������ı��������� robots.txt �ļ������磬Notepad��TextEdit��vi �� emacs ���Á턓����Ч�� robots.txt �ļ���Ո��ʹ������̎��ܛ���������ܛ��ͨ�������ļ�����錣�и�ʽ���ҿ��ܕ����ļ������ӷ��A�ڵ��ַ����珝��̖�����@�ӿ��ܕ��oץȡ���ߎ��톖�}����������ļ��r���F����ϵ�y��ʾ��Ո�ձ�ʹ�� UTF-8 ���a�����ļ���
��ʽ��λ��Ҏ�t��
�� �ļ���������� robots.txt��
�� �Wվֻ���� 1 �� robots.txt �ļ���
�� robots.txt �ļ����λ����Ҫ���õ��ľWվ���C�ĸ�Ŀ��¡����磬��Ҫ���ƌ� https://www.example.com/ �����оWַ��ץȡ���ͱ�회� robots.txt �ļ����� https://www.example.com/robots.txt �£�һ�����܌��������Ŀ��У����� https://example.com/pages/robots.txt �£�����������_������L���Լ��ľWվ��Ŀ䛣�������Ҫ�����������L����Ո�c�Wվ�йܷ����ṩ��ϵ��������o���L���Wվ��Ŀ䛣�Ո�����������η���������Ԫ��ӛ����
�� robots.txt �ļ��ɑ��õ��ӾW������ https://website.example.com/robots.txt����ǘ˜ʶ˿ڣ����� http://example.com:8181/robots.txt����
�� robots.txt �ļ�����Dz��� UTF-8 ���a������ ASCII�����ı��ļ���Google ���ܕ����Բ����� UTF-8 �������ַ����Ķ����ܕ����� robots.txt Ҏ�t�oЧ��
Ҏ�t���P��ץȡ���߿���ץȡ�Wվ��Щ���ֵ��f������ robots.txt �ļ�������Ҏ�t�r��Ո��ѭ���ʄt��
�� robots.txt �ļ�����һ��������M��
�� ÿ���M�ɶ��lҎ�t��ָ�����M�ɣ�ÿ�lָ���ռһ�С�ÿ���M���� User-agent ���_�^��ԓ��ָ���˽M�m�õ�Ŀ�ˡ�
�� ÿ���M����������Ϣ��
* �M���m������������
* ���������L����Ŀ䛻��ļ���
* ����o���L����Ŀ䛻��ļ���
�� ץȡ���ߕ������ϵ��µ����̎���M��һ���Ñ�����ֻ��ƥ�� 1 ��Ҏ�t�������c�����Ñ�����ƥ��ı��^�������w�M����
�� ϵ�y��Ĭ�J���O�ǣ��Ñ���������ץȡ����δ�� disallow Ҏ�t���εľW퓻�Ŀ䛡�
�� Ҏ�t�^�ִ�С�������磬disallow: /file.asp �m���� https://www.example.com/file.asp�������m���� https://www.example.com/FILE.asp��
�� # �ַ���ʾעጵ��_ʼ̎��
Google ��ץȡ����֧�� robots.txt �ļ��е�����ָ�
�� user-agent: [���裬ÿ���M�躬һ������� User-agent �lĿ] ԓָ��ָ����Ҏ�t�m�õ��Ԅӿ͑��ˣ�����������ץȡ���ߣ������Q���@��ÿ��Ҏ�t�M�����Ѓ��ݡ�Google �Ñ������б����г��� Google �Ñ��������Q�� ʹ����̖ (*) ��ƥ������N AdsBot ץȡ����֮�������ץȡ���ߣ�AdsBot ץȡ���߱�����_ָ�������磺
# Example 1: Block only Googlebot
User-agent: Googlebot
Disallow: /
# Example 2: Block Googlebot and Ad***ot
User-agent: Googlebot
User-agent: AdsBot-Google
Disallow: /
# Example 3: Block all but AdsBot crawlers
User-agent: *
Disallow: /
�� disallow: [ÿ�lҎ�t�躬����һ������� disallow �� allow �lĿ] ����ϣ���Ñ�����ץȡ��Ŀ䛻�W퓣������ڸ��W����ԣ������Ҏ�t������ij���W퓣��t����ṩ�g�[�����@ʾ�������W����Q��������� / �ַ��_�^�������������ij��Ŀ䛣��t����� / ��ӛ�Yβ��
�� allow: [ÿ�lҎ�t�躬����һ������� disallow �� allow �lĿ] �������ᵽ���Ñ���������ץȡ��Ŀ䛻�W퓣������ڸ��W����ԣ�����ָ��������Q disallow ָ��Ķ����Sץȡ�ѽ�ֹ�L����Ŀ��е���Ŀ䛻�W퓡����چ��W퓣�Ոָ���g�[�����@ʾ�������W����Q������Ŀ䛣�Ո�� / ��ӛ�Y��Ҏ�t��
�� sitemap: [���x��ÿ���ļ��ɺ��む����� sitemap �lĿ] �����Wվ��վ�c�؈D��λ�á�վ�c�؈D�Wַ�������ȫ���ľWַ��Google �����ٶ����ڻ�z���Ƿ���� http��https��www���� www �Wַ׃�w��վ�c�؈D��һ�N����ָʾ Google ��ץȡ��Щ���ݵ����뷽ʽ������������ָʾ Google ����ץȡ����ץȡ��Щ���ݡ�Ԕ���˽�վ�c�؈D�� ʾ����
Sitemap: https://example.com/sitemap.xml
Sitemap: http://www.example.com/sitemap.xml
�� sitemap ֮�������ָ�֧��ʹ��ͨ��� * ��ʾ·��ǰ�Y����Y�������ַ�����
�c�@Щָ�����ƥ����Ќ������ԡ�
�������Pÿ��ָ��������f����Ո��� Google �� robots.txt Ҏ���Ľ����档
�� robots.txt �ļ����浽Ӌ��C��������Ԍ����ṩ�o��������ץȡ���ߡ��]��һ���yһ���߿��Ԏ���������@헹����������Ό� robots.txt �ļ��ς����Wվȡ�Q�����ľWվ�ͷ������ܘ���Ո�c�����йܹ�˾ϵ�������йܹ�˾���ęn���M�����������磬����"�ς��ļ� infomaniak"��
�ς� robots.txt �ļ���Ո�yԇԓ�ļ��Ƿ�ɹ��_�L�����Լ� Google �ܷ����ԓ�ļ���
Ҫ�yԇ���ς��� robots.txt �ļ��Ƿ�ɹ��_�L����Ո�ڞg�[���д��_�o�۞g�[���ڣ����Ч���ڣ���Ȼ���D�� robots.txt �ļ���λ�á����磺https://example.com/robots.txt����������� robots.txt �ļ��ă��ݣ��Ϳɜʂ�yԇ��ӛ�ˡ�
Google �ṩ�˃ɷN�yԇ robots.txt ��ӛ�ķ�ʽ��
1��Search Console �е� robots.txt �yԇ���ߡ���ֻ��ᘌ����Wվ�Ͽɹ��L���� robots.txt �ļ�ʹ�ô˹��ߡ�
2����������_�l�ߣ�Ո�˽Ⲣ���� Google ���_Դ robots.txt �죬ԓ��Ҳ���� Google �����С�������ʹ�ô˹�����Ӌ��C�ϱ��yԇ robots.txt �ļ���
�����ς����yԇ robots.txt �ļ���Google ��ץȡ���ߕ��Ԅ��ҵ����_ʼʹ������ robots.txt �ļ������o���ȡ�κβ���������������� robots.txt �ļ�������Ҫ�M��ˢ�� Google �ľ��渱����Ո�˽�����ύ���º�� robots.txt �ļ���
������һЩ��Ҋ�Č��� robots.txt Ҏ�t��
����Ҏ�t��ֹץȡ�����WվՈע�⣬��ijЩ��r�£�Google ��ʹδץȡ�Wվ�ľWַ���Կ��܌��侎��������TAG���ȸ�����������ô����
�������Wվ�o������������@ȡ������ӆ�Σ��f�����һ�_ʼ�͛]�н������_��SEO���ԡ�

1�������P�I�~����,�����P�I�~ָ��,���ɔUչ.
2�������Ñ��������T������SEOҎ�t�������\�I.
3�����I�Fꠌ�ʩ������������Ч�����m�б���.

1���Wվ�Y�����Ȳ��˺���HTML���a�ȸ�����SEOҎ�t.
2���͑�ָ���P�I�~�������P�I�~ָ����������퓲����M.
3����������֩��ץȡЧ�ʡ����Ч�ʡ�����չ�F����Ч�L��.

1���������ַ������˽�ͬ�РI�N�����Լ��ИIڅ��.
2���P�I�~���C���ȸ���퓎����߃rֵ������ԃ�P.
3�����wGoogle��Bing��Yahoo���������������Ѻ�ץȡ.
�����ϏIJ�ȱ�aƷ��ȱ���ǰѮaƷ�u��ȥ�ķ������ƃ����DZ������I��SEO��˾,��ע�ٶȡ��ȸ衢�ѹ���360���������惞�����ա��҂������Ñ��������T������SEOҎ�t�������Wվ�\�I��SEO�������g��
ͬ�ȳɱ�,�����P�I�~��������ǰ;ͬ���Ј�,�����i��Ŀ�˿͑���������ԃ�P
��SEO���g�͑��ѵ��㣡���Ʒ���~�������~�ͮaƷ�~�M���ܶ��ռλ��������͑������㣡���M�Ñ��w�ֱ�_���퓣������Ñ���ԃ���A�s���ԣ�ͻ���aƷ����u�c���ð����͙����������Ʒ�ƹ������͑��x���㣡
SEO�Wվ������һ헳��m�Ҿ������Ĺ���������һ�����ݡ���Ҫ���������Pע�ИI�ӑB����������������������@Щ���첻���{���̓������ԡ��ƃ������ţ���SEO���ó��У����ĺ������Dz��ɻ�ȱ��������ֻ�г�֮�Ժ��Ͷ��Ŭ�������������Wվ�������ڼ��ҵľW�j�h����Ó�f������ȡ�ø��郞������������������

�������惞���۽���վ�ȃ�����վ��SEO�������w�Կ͑������ģ����D���rֵ�����ѭ�Ñ����������Ҏ�t���dzɹ����P�I���������郞����һ�h�����HҪ�M���x�ߣ�߀�������������ץȡҎ�t������䛵����²��ЙC�����c������ˣ����_���}�������Y�����������������Y���P�I�~�c���}��SEOҎ�t�����������°l���ı�Ҫ�ء�

�������惞����SEO���c���r�ƏV��ͬ��������������I�N��SEM�������侫�ʝM��͑��������ɞ���С��I�Wվ�I�N�ă��x��SEM�������������@һ�����м~�����ʲ��@Ŀ�˿͑�������Ʒ�ƽ��O���oՓ�ڇ����Ј��������ٶȡ��ѹ���360��߀�LJ��H�Ј������ùȸ衢�ؑ����Ż���SEM���ܳɞ����I�N�ď����������oՓ����߀�LJ��H��SEM����һ헸�Ч�����ʵĠI�N���ԡ�

�S����������SEOЧ�����ɣ����ƃ����J�飬�@�����c�WվSEO�������P���P�I�~�����m�ܶ�����Ӱ푣������_˼�S��Ҏ���������P�I���ھWվ�Ͼ�ǰ������������{��SEO���_��վ�ȃ�����λ��ƽ���Ñ��������������Ҏ�t���������Wվ�D���ʡ���ˣ��ƌW��SEO���Ԍ������Wվȡ�ø���Ч����
