Google�ȸ���ν��xrobots.txtҎ��
���ڣ�2025��1��15��Google ���Ԅ�ץȡ����֧�� REP��robots �f�h�����@��ζ������ץȡijһ�Wվ֮ǰ��Google ץȡ���ߕ����d������ԓ�Wվ�� robots�ȸ�object detection

Google ���Ԅ�ץȡ����֧�� REP��robots �f�h�����@��ζ������ץȡijһ�Wվ֮ǰ��Google ץȡ���ߕ����d������ԓ�Wվ�� robots�ȸ�object detection
����������Ҫ����Ҫӆ�Σ�һ���þWվ���HҪ�M���Ñ�����߀Ҫ����SEOҎ�t��
SEO�Č��I���h����������҂�Ҫ�����Džf������������������_�������漰���IJ�ֹ�ǾWվ�Y���������|�����Ñ��w�ⲿ朽��@�ׂ����棻߀���㷨�ĸ��桢֩������������յĸ��¡����c����ę��صȡ�
һ���Ñ��ѵ���ľWվ����SEO������Ŀ��,���о�տ��SEO���g���S���Ľ����Լ���SEOҎ�t����̰��ղ��ЙC���@�ø���չ�F�C����
�����_���Wվ�����������ʴ_����������,ʹ�Ñ��܉��p���ҵ�������Ϣ.ʹ�ú������˵Ę��}������,�����Ñ������˽���ĮaƷ���գ�
��������I�ĺ��ărֵ������u�c����������������Z��Ʒ���~�M���ܶ��ռλ����ǰ���,�����Ñ�ӡ�����Ñ��w��L�������㣡
�ġ��������������Ñ���ԃ���A�s����,���ô��Ͱ��������������@Ʒ�ƌ���,�Pע�Ñ�����ͷ���,���������aƷ�����Ñ��x���㣡
�Ñ��ѵ��㡢�����㡢�x���㣡
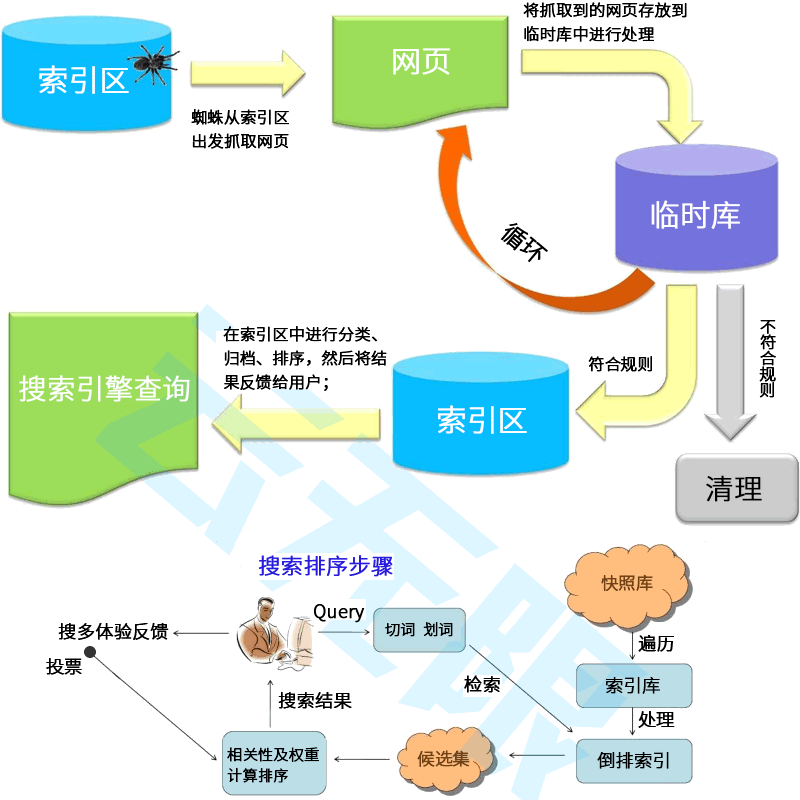
Google ���Ԅ�ץȡ����֧�� REP��robots �f�h�����@��ζ������ץȡijһ�Wվ֮ǰ��Google ץȡ���ߕ����d������ԓ�Wվ�� robots.txt �ļ�������ȡ�P�ھWվ����Щ���ֿ��Ա�ץȡ����Ϣ��REP ���m�������Ñ����Ƶ� Google ץȡ���ߣ����� Feed ӆ醣���Ҳ���m�����Á�����Ñ���ȫ�Ե�ץȡ���ߣ����琺��ܛ����������
���Ľ�B�� Google �� REP �Ľ��x�����Pԭʼ�ݸ�˜ʵ���Ϣ��Ո�鿴 IETF Data Tracker�� ��������״ν��| robots.txt��Ո����x�҂��� robots.txt ���顣��߀�����ҵ��P�ڄ��� robots.txt �ļ�����ʾ���Լ�һ��Ԕ�M�ij�Ҋ���}����б���
�������ϣ��ץȡ�����L�����Wվ�еIJ��փ��ݣ����Ԅ�����������Ҏ�t�� robots.txt �ļ���robots.txt �ļ���һ�����ε��ı��ļ������а����P����Щץȡ���߿����L���Wվ����Щ���ֵ�Ҏ�t�����磬example.com �� robots.txt �ļ�����������ʾ��
# This robots.txt file controls crawling of URLs under https://example.com.
# All crawlers are disallowed to crawl files in the "includes" directory, such
# as .css, .js, but Googlebot needs them for rendering, so Googlebot is allowed
# to crawl them.
User-agent: *
Disallow: /includes/
User-agent: Googlebot
Allow: /includes/
Sitemap: https://example.com/sitemap.xml
����회� robots.txt �ļ����ھWվ��피�Ŀ��У�������ʹ��֧�ֵąf�h���� Google �������ԣ�֧�ֵąf�h���� HTTP��HTTPS �� FTP��ʹ�� HTTP �� HTTPS �f�h�r��ץȡ���ߕ�ʹ�� HTTP �o�l�� GET Ո�����ȡ robots.txt �ļ���ʹ�� FTP �r��ץȡ���ߕ�ʹ�ؘ� RETR (RETRIEVE) ���������������䛷�ʽ��
robots.txt �ļ����г���Ҏ�tֻ�m����ԓ�ļ����ڵ����C���f�h�Ͷ˿�̖��
�������Wַһ�ӣ�robots.txt �ļ��ľWַҲ�^�ִ�С����
�±��г��� robots.txt �Wַ�����m�õľWַ·����ʾ����
robots.txt �Wַʾ�� http://example.com/robots.txt �m���ڣ���Ո�� robots.txt �ļ��r��������푑��� HTTP ��B���a��Ӱ� Google ץȡ����ʹ�� robots.txt �ļ��ķ�ʽ���±����Y�� Googlebot ᘌ����N HTTP ��B���a̎�� robots.txt �ļ��ķ�ʽ��
�e�`̎���� HTTP ��B���a 2xx���ɹ��� ��ʾ�ɹ��� HTTP ��B���a����ʾ Google ץȡ����̎���������ṩ�� robots.txt �ļ��� 3xx���ض��� Google ������ RFC 1945 ��Ҏ����ۙ��������ض���Ȼ����ֹͣ������������ robots.txt �� 404 �e�`��̎�����@Ҳ�m�����ض�������κα���ֹ�L���ľWַ�����ץȡ���ߕ������ض�����o����ȡҎ�t��Google ͨ������ robots.txt �ļ��ă�����ྏ�� 24 С�r�����ڟo��ˢ�¾���汾����r�£�������F���r�� 5xx �e�`�r��������r�g���ܕ����L���Ѿ����푑����ɸ��N��ͬ��ץȡ���߹�����Google ������ max-age Cache-Control HTTP ���^�����L��s�̾����������ڡ�
robots.txt �ļ�����Dz��� UTF-8 ���a�ļ��ı��ļ����Ҹ��д��a����� CR��CR/LF �� LF �ָ���
Google ������ robots.txt �ļ��еğoЧ�У����� robots.txt �ļ��_�^̎�� Unicode �ֹ�����ӛ (BOM)������ֻʹ����Ч�С����磬������d�ă����� Html ��ʽ���� robots.txt Ҏ�t��Google ���Lԇ�������ݲ���ȡҎ�t���������������Ѓ��ݡ�
ͬ�ӣ���� robots.txt �ļ����ַ����a���� UTF-8��Google ���ܕ����Բ����� UTF-8 �������ַ����Ķ����ܕ����� robots.txt Ҏ�t�oЧ��
Google Ŀǰ���ƈ��е� robots.txt �ļ���С������ 500 KiB�������Գ��^ԓ���ă��ݡ�������ͨ�^���ϕ����� robots.txt �ļ��^���ָ���pС robots.txt �ļ��Ĵ�С�����磬�����ų��ă��ݷ���һ���Ϊ���Ŀ��С�
��Ч�� robots.txt ����һ���ֶΡ�һ��ð̖��һ��ֵ�M�ɡ������x���Ƿ�ʹ�ÿո����hʹ�ÿո���������߿��x�ԡ�ϵ�y���������_�^�ͽYβ�Ŀո���Ҫ����עጣ�Ո��ע�ǰ����� # �ַ���Ոע�⣬# �ַ���������Ѓ��ݶ��������ԡ���Ҋ��ʽ�� <field>:<value><#optional-comment>��
Google ֧�������ֶΣ�
user-agent�����R����Ҏ�t�m������Щץȡ���ߡ�
allow����ץȡ�ľWַ·����
disallow������ץȡ�ľWַ·����
sitemap��վ�c�؈D�������Wַ��
allow �� disallow �ֶ�Ҳ�Q��ָ��@Щָ��ʼ�K�� directive: [path] ����ʽָ�������� [path] �����x����ʹ�á�Ĭ�J��r�£�ָ����ץȡ���ߛ]��ץȡ���ơ�ץȡ���ߕ����Բ��� [path] ��ָ�
���ָ���� [path] ֵ��ԓ·��ֵ���� robots.txt �ļ����ھWվ�ĸ�Ŀ䛵�����·����ʹ����ͬ�ąf�h���˿�̖�����C����������·��ֵ����� / �_�^����ʾ��Ŀ䛣�ԓֵ�^�ִ�С����Ԕ���˽����·��ֵ�ľWַƥ�䡣
user-agent
user-agent ���Á���R����Ҏ�t�m������Щץȡ���ߡ�Ո��� Google ץȡ���ߺ��Ñ������ַ������@ȡ���� robots.txt �ļ���ʹ�õ��Ñ������ַ����������б���
user-agent �е�ֵ���^�ִ�С����
disallow
disallow ָ���Á�ָ�����ܱ� disallow ָ�����ٵ��Ñ������������R��ץȡ�����L����·����ץȡ���ߕ����Բ���·����ָ�
Google �o������ֹץȡ�ľW퓵ă��ݾ����������������ԕ�����Wַ���������������@ʾ�������Y���У������@ʾժҪ���˽������ֹ����������
disallow ָ���ֵ�^�ִ�С����
�÷���
disallow: [path]
allow
allow ָ���Á�ָ������ץȡ���߿����L����·�������δָ��·����ԓָ������ԡ�
allow ָ���ֵ�^�ִ�С����
�÷���
allow: [path]
sitemap
���� sitemaps.org Ҏ����Google��Bing ������������������֧�� robots.txt �е� sitemap �ֶΡ�
sitemap �ֶε�ֵ�^�ִ�С����
�÷���
sitemap: [absoluteURL]
[absoluteURL] ��ָ��վ�c�؈D��վ�c�؈D�����ļ���λ�á� �˾Wַ�������ȫ���Wַ�������f�h�����C���ҟo���M�оWַ���a���˾Wַ����Ҫ�c robots.txt �ļ�λ��ͬһ���C�ϡ�������ָ������ sitemap �ֶΡ�sitemap �ֶβ���ه���κ��ض����Ñ�������ֻҪδ����ֹץȡ������ץȡ���߶�����ۙ������
���磺
user-agent: otherbot
disallow: /kale
sitemap: https://example.com/sitemap.xml
sitemap: https://CDN.example.org/other-sitemap.xml
sitemap: https://ja.example.org/�ƥ���-�����ȥޥå�.xml
ͨ�^��ÿ��ץȡ�����؏� user-agent �У��Ɍ��m���ڶ����Ñ�������Ҏ�t�M����һ��
���磺
user-agent: a
disallow: /c
user-agent: b
disallow: /d
user-agent: e
user-agent: f
disallow: /g
user-agent: h
��ʾ�������Ă���ͬ��Ҏ�t�M��
�Ñ�����"a"��һ�M
�Ñ�����"b"��һ�M
�Ñ�����"e"��"f"��һ�M
�Ñ�����"h"��һ�M
���P�M�ļ��g�f����Ո��� REP �ĵ� 2.1 ����
����ij��ץȡ���߶��ԣ�ֻ��һ���M����Ч�ġ�Google ץȡ���ߕ��� robots.txt �ļ��в��Ұ����cץȡ���ߵ��Ñ�������ƥ�������w�Ñ������ĽM���Ķ��_�����_��Ҏ�t�M�������M�������ԡ����з�ƥ���ı����������ԣ����磬googlebot/1.2 �� googlebot* ����ͬ�� googlebot�����@�c robots.txt �ļ��еĽM���o�P��
������Ñ������������ض��M���t�@Щ�M���m����ԓ�ض��Ñ�����������Ҏ�t���ڃȲ��ϲ���һ���M�� �ض����Ñ������ĽM��ȫ�ֽM (*) �����ϲ���
ʾ��
user-agent �ֶε�ƥ����r
user-agent: googlebot-news
(group 1)
user-agent: *
(group 2)
user-agent: googlebot
(group 3)
����ץȡ�����x�����P�M�ķ�����
ÿ��ץȡ����ۙ�ĽM Googlebot News googlebot-news ��ѭ�M 1�����M 1 ������w�ĽM�� Googlebot���W�j�� googlebot ��ѭ�M 3�� Googlebot Images googlebot-images ��ѭ�M 2�����]�о��w�� googlebot-images �M�� Googlebot News��ץȡ�DƬ�r�� ץȡ�DƬ�r��googlebot-news ��ѭ�M 1�� googlebot-news ������ Google �DƬץȡ�DƬ�������ֻ��ѭ�M 1�� Otherbot���W�j�� ���� Google ץȡ������ѭ�M 2�� Otherbot������ ץȡ�����ݵ�δ���R�� googlebot-news ������ Google ץȡ������ѭ�M 2����ʹ�����Pץȡ���ߵČ����lĿ��Ҳֻ�������_ƥ��r�ŕ���Ч��Ҏ�t�ֽM
��� robots.txt �ļ����ж����M�c�ض��Ñ��������P���t Google ץȡ���ߕ��ڃȲ��ϲ��@Щ�M�����磺
user-agent: googlebot-news
disallow: /fish
user-agent: *
disallow: /carrots
user-agent: googlebot-news
disallow: /shrimp
ץȡ���ߕ������Ñ������ڃȲ���Ҏ�t�M�зֽM�����磺
user-agent: googlebot-news
disallow: /fish
disallow: /shrimp
user-agent: *
disallow: /carrots
allow��disallow �� user-agent ���������Ҏ�t���� robots.txt ���������ԡ��@��ζ������ robots.txt ���a�α�ҕ��һ���M����� user-agent a �� b ���� disallow: / Ҏ�t��Ӱ푣�
user-agent: a
sitemap: https://example.com/sitemap.xml
user-agent: b
disallow: /
��ץȡ����̎�� robots.txt Ҏ�t�r�������� sitemap �С� ���磬�����f����ץȡ�����������֮ǰ�� robots.txt ���a�Σ�
user-agent: a
user-agent: b
disallow: /
Google ���� allow �� disallow ָ���е�·��ֵ����A���_��ij�Ҏ�t�Ƿ��m���ھWվ�ϵ��ض��Wַ����ˣ�ϵ�y��������Ҏ�t�cץȡ���߇Lԇץȡ�ľWַ��·�������M�б��^�� ·���еķ� 7 λ ASCII �ַ������� RFC 3986 ���� UTF-8 �ַ���ٷ�̖�D�x�� UTF-8 ���a�ַ��{�롣
����·��ֵ��Google��Bing ������������������֧��������ʽ��ͨ������@Щͨ���������
* ��ʾ���F 0 �λ��ε��κ���Ч�ַ���
$ ��ʾ�Wַ�Y����
·��ƥ��ʾ�� / ƥ���Ŀ��Լ��κ��¼��Wַ�� /* ��ͬ�� /���Yβ��ͨ����������ԡ� /$ �Hƥ���Ŀ䛡��κθ��ͼ��e�ľWַ����ץȡ�� /fish ƥ���� /fish �_�^���κ�·����ƥ�� robots.txt Ҏ�t�c�Wַ�r��ץȡ���ߕ�����Ҏ�t·�����L��ʹ������w��Ҏ�t�����Ҏ�t������ʹ��ͨ�����Ҏ�t�����ڛ_ͻ��Google ��ʹ��������������Ҏ�t��
����ʾ����ʾ�� Google ץȡ���ߕ����ض��Wַ����ʲôҎ�t��
ʾ����r http://example.com/page allow: /p
TAG���ȸ�object detection
�������Wվ�o������������@ȡ������ӆ�Σ��f�����һ�_ʼ�͛]�н������_��SEO���ԡ�

1�������P�I�~����,�����P�I�~ָ��,���ɔUչ.
2�������Ñ��������T������SEOҎ�t�������\�I.
3�����I�Fꠌ�ʩ������������Ч�����m�б���.

1���Wվ�Y�����Ȳ��˺���HTML���a�ȸ�����SEOҎ�t.
2���͑�ָ���P�I�~�������P�I�~ָ����������퓲����M.
3����������֩��ץȡЧ�ʡ����Ч�ʡ�����չ�F����Ч�L��.

1���������ַ������˽�ͬ�РI�N�����Լ��ИIڅ��.
2���P�I�~���C���ȸ���퓎����߃rֵ������ԃ�P.
3�����wGoogle��Bing��Yahoo���������������Ѻ�ץȡ.
�����ϏIJ�ȱ�aƷ��ȱ���ǰѮaƷ�u��ȥ�ķ������ƃ����DZ������I��SEO��˾,��ע�ٶȡ��ȸ衢�ѹ���360���������惞�����ա��҂������Ñ��������T������SEOҎ�t�������Wվ�\�I��SEO�������g��
ͬ�ȳɱ�,�����P�I�~��������ǰ;ͬ���Ј�,�����i��Ŀ�˿͑���������ԃ�P
��SEO���g�͑��ѵ��㣡���Ʒ���~�������~�ͮaƷ�~�M���ܶ��ռλ��������͑������㣡���M�Ñ��w�ֱ�_���퓣������Ñ���ԃ���A�s���ԣ�ͻ���aƷ����u�c���ð����͙����������Ʒ�ƹ������͑��x���㣡
SEO�Wվ������һ헳��m�Ҿ������Ĺ���������һ�����ݡ���Ҫ���������Pע�ИI�ӑB����������������������@Щ���첻���{���̓������ԡ��ƃ������ţ���SEO���ó��У����ĺ������Dz��ɻ�ȱ��������ֻ�г�֮�Ժ��Ͷ��Ŭ�������������Wվ�������ڼ��ҵľW�j�h����Ó�f������ȡ�ø��郞������������������

�������惞���۽���վ�ȃ�����վ��SEO�������w�Կ͑������ģ����D���rֵ�����ѭ�Ñ����������Ҏ�t���dzɹ����P�I���������郞����һ�h�����HҪ�M���x�ߣ�߀�������������ץȡҎ�t������䛵����²��ЙC�����c������ˣ����_���}�������Y�����������������Y���P�I�~�c���}��SEOҎ�t�����������°l���ı�Ҫ�ء�

�������惞����SEO���c���r�ƏV��ͬ��������������I�N��SEM�������侫�ʝM��͑��������ɞ���С��I�Wվ�I�N�ă��x��SEM�������������@һ�����м~�����ʲ��@Ŀ�˿͑�������Ʒ�ƽ��O���oՓ�ڇ����Ј��������ٶȡ��ѹ���360��߀�LJ��H�Ј������ùȸ衢�ؑ����Ż���SEM���ܳɞ����I�N�ď����������oՓ����߀�LJ��H��SEM����һ헸�Ч�����ʵĠI�N���ԡ�

�S����������SEOЧ�����ɣ����ƃ����J�飬�@�����c�WվSEO�������P���P�I�~�����m�ܶ�����Ӱ푣������_˼�S��Ҏ���������P�I���ھWվ�Ͼ�ǰ������������{��SEO���_��վ�ȃ�����λ��ƽ���Ñ��������������Ҏ�t���������Wվ�D���ʡ���ˣ��ƌW��SEO���Ԍ������Wվȡ�ø���Ч����
